¿Data Vault vs. Data Mesh?
¿Debería seguir haciendo Data Vault si existe Data Mesh? En las últimas semanas y meses he recibido estas preguntas muy interesantes en varias ocasiones.

¿Debería seguir haciendo Data Vault si existe Data Mesh? En las últimas semanas y meses he recibido estas preguntas muy interesantes en varias ocasiones. Así que aquí intento explicar mi entendimiento y mis reflexiones. Si tiene una opinión diferente, no dude en contactarme en LinkedIn para discutirlo. Si he malinterpretado alguna parte del concepto Data Mesh, hágamelo saber.
Puede ser útil entender mi trayectoria y lo que ha formado mi opinión. Trabajo con datos desde el año 2000. He visto distintas evoluciones tecnológicas como clientes Sybase migrando a Oracle, y clientes Oracle migrando a bases en la nube como Snowflake. He visto enfoques de modelado Inmon 3NF a veces reemplazados o complementados por modelado dimensional y el auge del modelado Data Vault.
Siempre he visto el modelado Data Vault como una evolución del modelado Inmon 3NF, a usar en muchos casos junto con una salida dimensional para reporting.
A lo largo de los últimos 22 años también hemos visto, una y otra vez, a usuarios de negocio esperando una entrega más rápida de informes — comprensión más sencilla de los datos y muchas más cosas. El resultado de tales demandas a veces conducía a una tecnología distinta o a un enfoque de modelado diferente.
En otros casos iniciaba una discusión sobre cuánto debe centralizarse (equipo especializado) o descentralizarse. Esta tensión no es nueva.
Entiendo, y es mi opinión personal: Data Mesh es una respuesta al reto de que el equipo de datos central pueda convertirse en un cuello de botella en ciertas empresas que usan un enfoque centralizado. Y entiendo perfectamente esa situación.
Como resultado, comparto muchos puntos de vista expresados en el trabajo de Zhamak Dehghani. Aun así, creo que este enfoque se aplica mejor a algunas grandes empresas con los recursos para añadir especialistas de datos en distintos dominios.
Mi argumento es que las empresas medianas e incluso más grandes podrían beneficiarse mejor de equipos centralizados usando automatización dirigida por modelos para eliminar el cuello de botella en los equipos centralizados como solución alternativa. Podría estar sesgado al trabajar para Datavault Builder — la automatización DWH es nuestro fuerte.
¿Data Vault vs. Data Mesh?
Si prefiere ver un vídeo en lugar de leer, puede encontrar la grabación de la conferencia Knowledge Gap aquí.
Significativamente acortado y según mi interpretación: Data Mesh describe que los Enterprise Data Models están muertos. Debería dividir su modelado e implementación de sus «flujos de datos» en dominios y asignarlos a equipos independientes — los dominios.
¿Significa esto que Data Vault queda eliminado de la ecuación? Yo no lo creo.
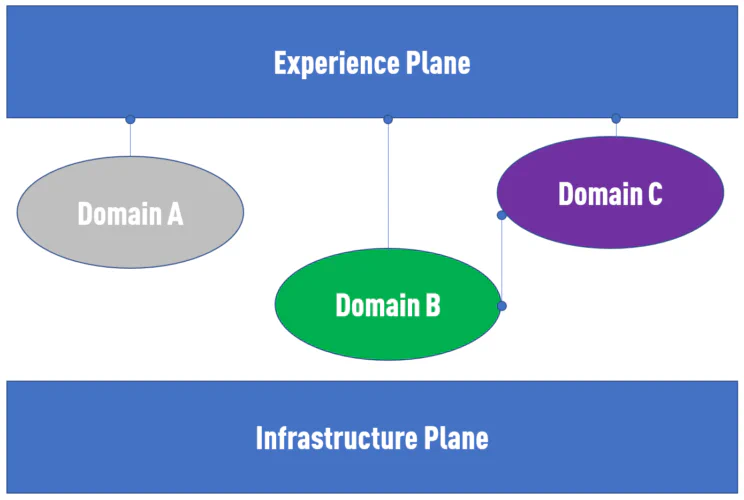
Vemos distintos proveedores de data products entre la infraestructura y el «Mesh Experience Plane». Data Mesh no prescribe a los equipos de dominio cómo crearlos. En muchos casos abogaría por que este sea el lugar perfecto para usar un enfoque Data Vault automatizado.
¿Por qué? Si quedó atascado con enfoques ETL en el pasado, dividirlos en dominios más pequeños puede resolver el problema de escalabilidad del equipo central de datos y reducir parte de la complejidad. Aun así, no elimina muchos otros problemas, como falta de documentación o mucho trabajo manual.
Los enfoques basados en modelos empiezan al revés, con la comprensión de qué son los datos. También tuvimos malas experiencias con Enterprise Data Models en el pasado: tardaban meses en crearse, requerían un doctorado para entenderse, y el equipo de datos los ignoraba por ser demasiado abstractos.
Aun así, los necesitamos porque aportan mucho valor y resuelven muchos problemas — pero necesitamos el enfoque correcto.
Data Vault resolvió problemas del modelo de datos empresarial 3NF usando acoplamiento débil entre entidades, permitiéndole empezar pequeño, implementarlo de inmediato y expandirlo después.
Como contrapartida, Data Vault crea, por hipernormalización, muchos objetos técnicos. El resultado es que necesitaría muchos data engineers en sus equipos de dominio para implementar manualmente un Data Vault.
Y aquí puedo volver a mi tema favorito: la automatización. La automatización le ayudará dentro de los dominios a reducir la cantidad de trabajo necesario para implementar sus Data Products transformando automáticamente un modelo de datos en código funcional.
También resolverá muchos de los requisitos definidos por Zhamak Dehghani, como obtener un data lineage claro y resolver la historización de los datos.
Por ejemplo, en Datavault Builder también obtendrá infraestructura automatizada, interfaces para inyectar sus sidecars y herramientas visuales para definir sus Data Products.
El modelo se versiona usando el enfoque software estándar con GIT-flow, que resuelve cualquier problema esperable en el despliegue de modelos y data products.
A través del despliegue Docker y las APIs proporcionadas, puede configurar su workflow CI-CD de forma sencilla.
Como un enfoque Data Vault automatizado está dirigido por modelo, también le permitirá generar y consultar todos los metadatos del modelo y runtime sin desarrollo manual.
Creo que es una simbiosis perfecta. ¿Significa esto que cada dominio de datos debería usar una implementación Data Vault automatizada? Probablemente no.
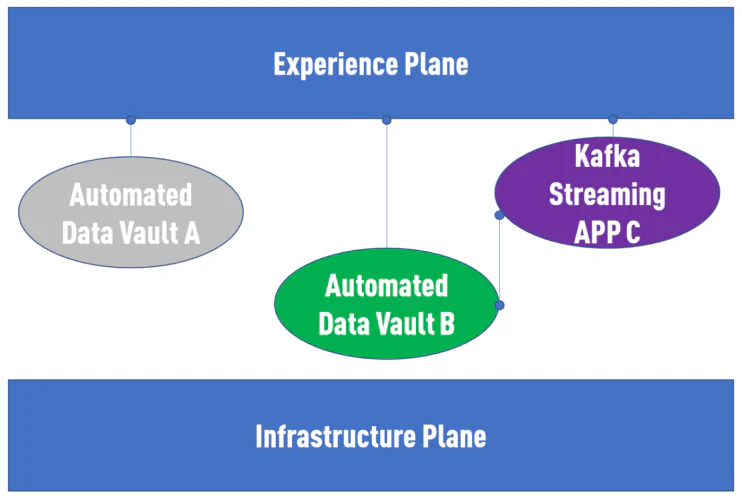
Para concluir: Data Mesh + Data Vault es la respuesta. Más precisamente: Data Mesh + Data Vault + Automatización.
Modelo de datos central vs. descentralizado
El libro «Data Mesh» permanece vago en los detalles concretos de implementación. Y por favor no me malinterprete: no es una crítica. Creo que tiene que ser así, ya que abre una visión que puede implementarse de muchas formas distintas.
Entendemos que la responsabilidad de modelado puede compartirse entre equipos — en términos Data Mesh, entre dominios. Lo hemos hecho durante años, por ejemplo, en empresas multinacionales con un equipo central de plataforma y equipos locales de datos que conocen las especificidades del país.
El equipo central define entidades centrales como el «customer» o el «product». ¡Ahora los primeros, esperemos, empezarán a quejarse de que estamos creando otra vez los obstáculos que queríamos eliminar!
Escúcheme: no abogo por crear una implementación central de estos objetos. Solo una definición conceptual de que estos objetos existen. Esta definición abstracta correspondería a dibujar una entidad en su canvas en un mundo ER. En Data Vault sería un hub.
Una vez establecido que estos conceptos existen, puede distribuir estos «prototipos» en los distintos dominios. Cada dominio ejecutaría su propia instancia de Datavault Builder. Los equipos de dominio decidirán cómo rellenar estos conceptos con datos.
Este proceso de definir centralmente la existencia de cosas y distribuir las definiciones a los dominios de datos puede automatizarse completamente en Datavault Builder, gracias a modelos de datos que pueden ramificarse y fusionarse mediante un proceso GIT.
La ventaja es que si el equipo de revenue assurance crea una relación con la entidad «customer» creada centralmente, definirá cómo puede relacionar datos entre los dominios customer y revenue assurance de forma totalmente automática en el Experience Plane.
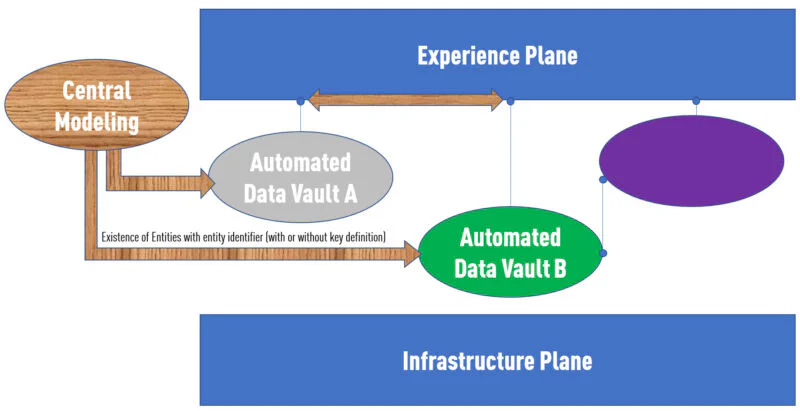
Cómo unir entre dominios de datos
Ahora que sabe cómo unir distintos data products desde una perspectiva lógica, queda la pregunta de cómo lograrlo técnicamente. En el libro Data Mesh se propone usar relaciones URI entre objetos. Este enfoque puede funcionar para consultas más pequeñas.
Como Datavault Builder es una herramienta ELT para la mayoría de las capas, almacenamos todos los resultados a nivel de base de datos con interfaces virtuales (vistas). Esto significa que aunque distintos dominios usando Datavault Builder tengan instancias completamente aisladas en bases distintas pero la misma tecnología, pueden hacer joins usando cross-database queries.
Si las distintas instancias no usan la misma tecnología de base de datos, puede usar productos de virtualización como Denodo.
Datavault Builder
En esta sección intento destacar por qué creemos que Datavault Builder es la herramienta adecuada para implementar Data Vault si crea una solución Data Mesh.
- Cloud-Native — puede ejecutarlo sobre un infrastructure plane estandarizado.
- Configuración automatizada de infraestructura — usando despliegue Docker.
- CI/CD — todas las acciones de despliegue pueden lanzarse vía APIs.
- Automatización dirigida por modelo — se necesitan menos habilidades técnicas en los dominios de datos.
- Basado en Git Flow — los modelos pueden ramificarse y fusionarse.
- Modelos centrales y distribuidos — capacidad integrada para crear elementos core centralmente.
- Composición visual de Data Products.
- Data lineage automatizado.
- Documentación automatizada.
- Todas las métricas disponibles en tiempo real.
- El enfoque Data Vault permite empezar pequeño y extender el modelo de dominio con el tiempo.
Vea Datavault Builder en acción
Demo en vivo. Respuestas honestas sobre si encaja con su equipo.
Reservar una Demo Gratuita