Data Vault vs. Data Mesh ?
Devrais-je encore faire du Data Vault s'il y a Data Mesh ? Au cours des dernières semaines et mois, j'ai reçu ces questions très intéressantes plusieurs fois.

Devrais-je encore faire du Data Vault s’il y a Data Mesh ? Au cours des dernières semaines et mois, j’ai reçu ces questions très intéressantes plusieurs fois. Je vais donc essayer d’expliquer ici ma compréhension et mes réflexions. Si vous avez un point de vue divergent, n’hésitez pas à me contacter sur LinkedIn pour en discuter. Si j’ai mal compris une partie du concept de Data Mesh, faites-le moi savoir.
Il pourrait être utile de comprendre mon parcours et ce qui a formé mon opinion. Je travaille avec les données depuis 2000. J’ai vu différentes évolutions technologiques comme les clients Sybase migrant vers Oracle et les clients Oracle migrant vers des bases cloud comme Snowflake. J’ai vu les approches de modélisation Inmon 3NF parfois remplacées ou complétées par la modélisation dimensionnelle et la montée en puissance de la modélisation Data Vault.
J’ai toujours vu la modélisation Data Vault comme une évolution de la modélisation Inmon 3NF, à utiliser dans de nombreux cas avec une sortie dimensionnelle pour le reporting.
Au cours des 22 dernières années, nous avons aussi vu, encore et encore, les utilisateurs métier espérer une livraison plus rapide des rapports — une compréhension plus simple des données et bien d’autres choses. Le résultat de telles demandes a parfois conduit à une technologie ou une approche de modélisation différente.
Dans d’autres cas, cela a déclenché une discussion sur le degré de centralisation (équipe spécialisée) ou de décentralisation. Cette tension n’est pas nouvelle.
Je comprends, et c’est mon opinion personnelle : Data Mesh est une réponse au défi qu’une équipe data centrale peut devenir un goulet d’étranglement dans certaines entreprises utilisant une approche centralisée. Et je comprends parfaitement cette situation.
En conséquence, je partage de nombreux points de vue exprimés dans le travail de Zhamak Dehghani. Néanmoins, je pense que cette approche s’applique le mieux à de grandes entreprises ayant les ressources pour ajouter des spécialistes data dans différents domaines.
Mon argument est que les entreprises de taille moyenne et même plus grandes pourraient mieux profiter des équipes centralisées en utilisant l’automatisation pilotée par modèle pour supprimer le goulet d’étranglement comme solution alternative. Je pourrais être biaisé puisque je travaille pour Datavault Builder — l’automatisation DWH est notre métier.
Data Vault vs. Data Mesh ?
Si vous préférez regarder une vidéo plutôt que lire, vous pouvez trouver l’enregistrement de la conférence Knowledge Gap ici.
Significativement raccourci et selon mon interprétation : Data Mesh décrit que les modèles de données d’entreprise sont morts. Vous devriez diviser votre modélisation et l’implémentation de vos « flux de données » en domaines et les attribuer à des équipes indépendantes — les domaines.
Cela signifie-t-il que Data Vault est retiré de cette équation ? Je ne le crois pas.
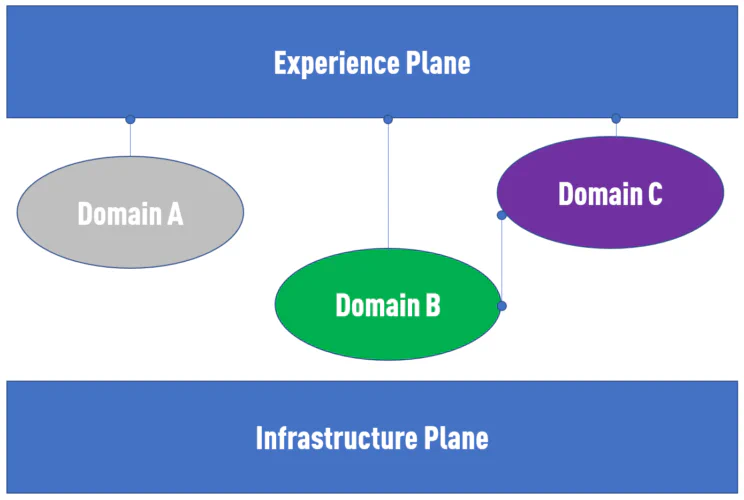
Nous voyons différents fournisseurs de data products entre l’infrastructure et le « Mesh Experience Plane ». Data Mesh ne prescrit pas aux équipes de domaine comment les créer. Dans de nombreux cas, je préconiserais que ce soit l’endroit parfait pour utiliser une approche Data Vault automatisée.
Pourquoi ? Si vous étiez bloqués avec des approches ETL par le passé, les diviser en domaines plus petits peut résoudre le problème de scalabilité de l’équipe data centrale et réduire une certaine complexité. Mais cela ne supprime pas de nombreux autres problèmes, comme le manque de documentation ou beaucoup de travail manuel.
Les approches pilotées par modèle commencent à l’inverse par la compréhension de ce que sont les données. Nous avons aussi eu de mauvaises expériences avec les Enterprise Data Models par le passé : il fallait des mois pour les créer, un doctorat pour les comprendre, et l’équipe data les ignorait car ils étaient trop abstraits.
Néanmoins, nous en avons besoin car ils apportent beaucoup de valeur et résolvent beaucoup de problèmes — mais nous avons besoin de la bonne approche.
Data Vault a résolu les problèmes du modèle de données d’entreprise 3NF en utilisant un couplage lâche entre les entités, vous permettant de commencer petit, de l’implémenter immédiatement et de l’étendre plus tard.
Du côté négatif, Data Vault crée, par hyper-normalisation, beaucoup d’objets techniques. Le résultat est que vous auriez besoin de beaucoup de data engineers dans vos équipes de domaine pour implémenter manuellement un Data Vault.
Et ici, je peux revenir à mon sujet préféré : l’automatisation. L’automatisation vous aidera dans les domaines à réduire la quantité de travail nécessaire pour implémenter vos Data Products en transformant automatiquement un modèle de données en code fonctionnel.
Elle résoudra également beaucoup d’exigences définies par Zhamak Dehghani, comme obtenir un data lineage clair et trier l’historisation des données.
Par exemple, dans Datavault Builder, vous obtiendrez aussi une infrastructure automatisée, des interfaces pour injecter vos sidecars et des outils visuels pour définir vos Data Products.
Le modèle est versionné en utilisant l’approche logicielle standard avec GIT-flow, ce qui résout tous les problèmes que vous pourriez attendre dans le déploiement de modèles et de data products.
À travers le déploiement Docker et les APIs fournies, vous pouvez configurer votre workflow CI-CD de manière simple.
Comme une approche Data Vault automatisée est pilotée par modèle, elle vous permettra aussi de générer et d’interroger toutes les métadonnées du modèle et du runtime sans aucun développement manuel.
Je pense que c’est une symbiose parfaite. Cela signifie-t-il que chaque domaine data devrait utiliser une implémentation Data Vault automatisée ? Probablement pas.
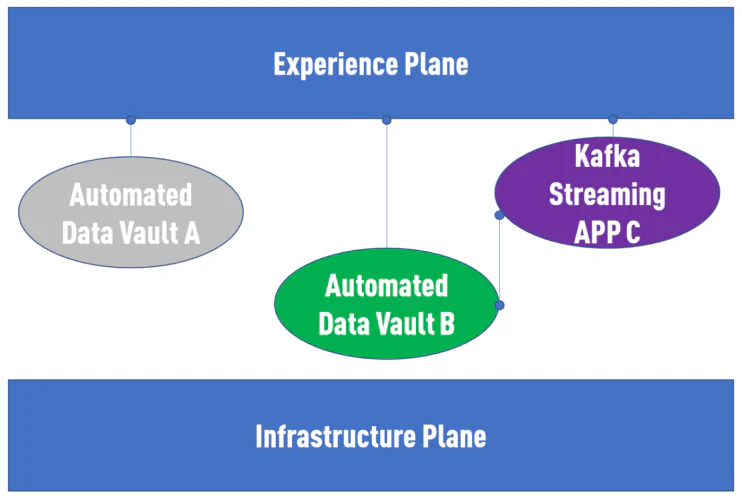
Pour conclure : Data Mesh + Data Vault est la réponse. Plus précisément : Data Mesh + Data Vault + Automatisation.
Modèle de données central vs. décentral
Le livre « Data Mesh » reste vague sur les détails d’implémentation spécifiques. Et ne vous méprenez pas : ce n’est pas une critique. Je pense qu’il le doit, car il ouvre une vision qui peut être implémentée de plusieurs façons. Mais de mon point de vue, je commence toujours à réfléchir à une implémentation concrète.
Nous comprenons que la responsabilité de la modélisation peut être partagée entre équipes — en termes Data Mesh, entre domaines. Nous le faisons depuis des années, par exemple dans des entreprises multinationales avec une équipe de plateforme centrale et des équipes data locales connaissant les spécificités du pays.
L’équipe centrale définit des entités centrales comme le « customer » ou le « product ». Maintenant, les premiers commencent, espérons-le, à se plaindre que nous créons à nouveau des goulets d’étranglement que nous voulions supprimer !
Écoutez-moi : je ne préconise pas de créer une implémentation centrale de ces objets. Juste une définition conceptuelle que ces objets existent. Cette définition abstraite correspondrait à dessiner une entité sur votre canvas dans un monde ER. Dans Data Vault, ce serait un hub.
Maintenant que vous avez établi que ces concepts existent, vous pouvez distribuer ces « prototypes » dans les différents domaines. Chaque domaine ferait tourner sa propre instance de Datavault Builder. Les équipes de domaine décideront comment remplir ces concepts avec des données.
Ce processus de définition centrale de l’existence des choses et de distribution des définitions aux domaines data peut être complètement automatisé dans Datavault Builder, grâce à des modèles de données qui peuvent être branchés et fusionnés via un processus GIT.
L’avantage est que si l’équipe revenue assurance crée une relation à l’entité « customer » créée centralement, elle définira comment vous pouvez relier les données entre les domaines customer et revenue assurance de manière entièrement automatique sur l’Experience Plane.
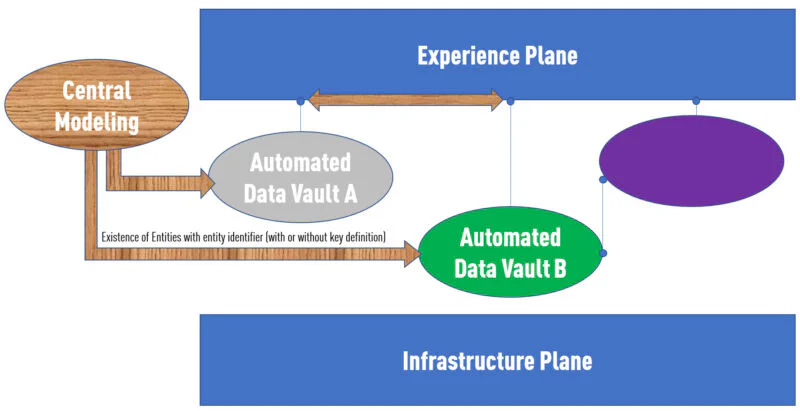
Comment joindre entre domaines data
Maintenant que vous savez comment joindre différents data products d’un point de vue logique, la question demeure de savoir comment y parvenir techniquement. Dans le livre Data Mesh, il est proposé d’utiliser des relations URI entre objets. Cette approche pourrait fonctionner pour des requêtes plus petites.
Comme Datavault Builder est un outil ELT pour la plupart des couches, nous stockons tous les résultats au niveau base de données avec des interfaces virtuelles (vues). Cela signifie que même si différents domaines data utilisant Datavault Builder ont des instances complètement isolées sur des bases de données séparées mais la même technologie, ils peuvent faire des joins en utilisant des cross-database queries.
Si différentes instances n’utilisent pas la même technologie de base de données, vous pouvez utiliser des produits de virtualisation comme Denodo.
Datavault Builder
Dans cette section, j’essaie de mettre en lumière pourquoi nous croyons que Datavault Builder est le bon outil pour implémenter Data Vault dans une solution Data Mesh.
- Cloud-Native — vous pouvez l’exécuter sur une infrastructure plane standardisée.
- Configuration automatisée de l’infrastructure — en utilisant le déploiement Docker.
- CI/CD — toutes les actions de déploiement peuvent être déclenchées via APIs.
- Automatisation pilotée par modèle — moins de compétences techniques nécessaires dans les domaines data.
- Basé sur Git Flow — les modèles de données peuvent être branchés et fusionnés.
- Modèles centraux et distribués — capacité intégrée à créer des éléments core centralement.
- Composition visuelle de Data Products.
- Data lineage automatisé.
- Documentation automatisée.
- Toutes les métriques disponibles en temps réel.
- L’approche Data Vault permet de commencer petit et d’étendre le modèle de domaine au fil du temps.
Voir Datavault Builder en action
Démo de 20 minutes. Réponses honnêtes sur l'adéquation avec votre équipe.
Réserver une démo gratuite