O Multi-Active satelitech v Data Vaultu
Petr Beles o implementaci Multi-Active satelitů jako Document satelitů v Data Vaultu: patterny, kompromisy a praktická doporučení.
Petr Beles, 2150 GmbH 2018-11-07
Implementace Multi-Active satelitů jako Document satelitů
V Data Vault standardu existuje pattern zvaný Multi-Active satelit. Částečně se také používá pro ukládání bi-temporality v Data Vaultu.
Byznysovému klíči v hubu s určitou granularitou je v satelitu k danému okamžiku (podle DWH znalosti nebo assertion time) přiřazeno více než jeden platný záznam.
Pokusím se vysvětlit, proč se v některých případech Multi-Active satelity používají, kdy by se bez nich měl člověk obejít a jak je lze implementovat, pokud se přesto rozhodne je používat.
Důvody pro použití Multi-Active satelitů
- Skutečně neexistuje klíč, který by rozlišil různé řádky pro stejný byznysový klíč
Ve skutečnosti je z mé zkušenosti tento případ vzácný a data jsou často špatně interpretována: i u zákazníka s různými neklasifikovanými telefonními čísly lze každé číslo jednoznačně identifikovat: podle čísla samotného.
Také: pokud neexistuje identifikátor, technické duplicity nelze ve zdrojovém rozhraní rozpoznat. Z mého pohledu by proto měl být zdrojový systém pokud možno vyzván k úpravě dodávky dat.
- Z výkonových důvodů
Pokud je dán jedinečný subklíč, můžete alternativně definovat další hub na jemnější granularitě a propojit ho čistě přes link jako alternativu k multi-active satelitu. To umožňuje používat standardní patterny pro plnění a dotazování, ale musíte načítat a dotazovat dva další objekty.
Důvody, proč nechcete používat Multi-Active satelity
Prvním problémem je, že multi-active satelit lze plnit delta načítáními pouze tehdy, pokud jsou v delta extraktu přítomny všechny řádky pro hub klíč. Alternativně jsou vždy možná plná načítání.
Další výzva se ukáže při dotazování multi-active satelitu spolu s hubem, protože odlišná granularita způsobuje duplikaci záznamů hubu (známé také jako fanning-out) — i při dotazu na daný assertion time.
V neposlední řadě uvažte, co se stane, když chcete vytvořit PIT pro dva nebo více multi-active satelitů na stejném hubu. Předpokládám, že skončíte v pekle kartézského součinu.
Ale nejdůležitějším argumentem podle mého názoru je, že pokud chcete propojit jemnější granularitu, měli byste z ní vytvořit vlastní hub. Vezměte si například pojistné smlouvy: instance pojistné smlouvy je rozhodně nezávislý objekt, ke kterému lze připojit pojistné události. Zde bych osobně vždy modeloval hub smlouvy a hub instance smlouvy místo multi-active satelitu.
Návrh řešení pro implementaci: Document satelit
Předpokládejme, že máme platný případ pro implementaci multi-active satelitu — jak by vypadal dobrý load pattern?
Na setkání německé Data Vault uživatelské skupiny (DDVUG) v Hamburku v říjnu 2018 jsme Torsten Glunde, Andreas Heitmann, Matthias Müller, někdo, jehož jméno mi uniklo, a já diskutovali o řešení, které by vyřešilo některé implementační problémy:
Pokud předpokládáme, že všechny aktivní řádky pro byznysový klíč musí být ve stagingu stejně přítomny najednou, můžete z těchto řádků vytvořit množinu.
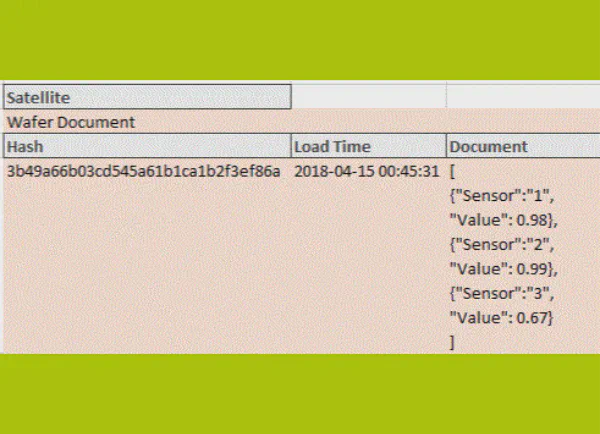
Existují databáze, které umožňují nativní pole jako typy polí, které lze použít pro ukládání množin. Realističtější dnes by mohl být JSON dokument, který je již podporován na většině platforem. Kromě hierarchií může JSON dokument reprezentovat i množiny.
Takže pokud uložíte všechny řádky do jednoho JSON dokumentu v jednom satelitním záznamu, granularita hubu a satelitu pro daný assertion time se opět shoduje. Lze tedy pro všechny satelity použít stejné, standardní load patterny.
Pro downstream zpracování navíc nedochází k žádnému zvýšení složitosti ani při vytváření PIT, ani v jiných čtecích vrstvách. Pokud (a pouze pokud) máte byznysový požadavek rozložit množinu na jednotlivé řádky (parsování JSON dokumentu v našem případě), můžete se tak rozhodnout. To se však děje vědomě na místě, kde je to žádoucí.
JSON dokumenty v databázích
S rostoucí popularitou JSON dokumentů přibývá i podpora pro práci s nimi v několika databázích, jako binární porovnání v PostgreSQL. Pomocí této funkce jsou ignorovány nepodstatné rozdíly v dokumentu a nový satelitní záznam se vkládá pouze tehdy, pokud se v obsahu skutečně něco změnilo.
Na druhé straně, pokud vaše databáze podporuje pouze textové porovnání JSON, museli byste přijmout aktivní opatření, abyste ignorovali nepodstatné rozdíly pomocí nějakého druhu prettify.
Epilog
Používání JSON v satelitech samozřejmě není novinkou a může být použito i v jiných případech: sám Dan Linstedt popsal použití JSON dokumentů pro zpracování dynamických zdrojových dat.
Vyzkoušejte Datavault Builder v akci
Živé demo. Upřímné odpovědi, zda je to pro váš tým.
Rezervovat bezplatné demo