À propos des Multi-Active Satellites dans Data Vault
Petr Beles sur l'implémentation des Multi-Active Satellites comme Document Satellites dans Data Vault : patterns, compromis et conseils pratiques.
Petr Beles, 2150 GmbH 2018-11-07
Implémenter des Multi-Active Satellites comme Document Satellites
Dans le standard Data Vault il existe un pattern appelé Multi-Active Satellite. Il est aussi en partie utilisé pour stocker la bi-temporalité dans le Data Vault.
Une business key dans un hub avec une certaine granularité se voit attribuer plus d’une entrée valide dans le satellite à un moment donné (selon la connaissance DWH ou assertion time).
Permettez-moi d’essayer d’expliquer pourquoi dans certains cas les Multi-Active Satellites sont utilisés, quand on devrait s’en passer et comment on pourrait les implémenter si on a quand même décidé de les utiliser.
Raisons d’utiliser des Multi-Active Satellites
- Il n’y a vraiment pas de clé pour distinguer les différentes lignes pour la même business key
En réalité, dans mon expérience c’est rarement le cas et les données sont souvent mal interprétées : même avec un client ayant différents numéros de téléphone non classés, chaque numéro peut être identifié de manière unique : par le numéro lui-même.
Aussi : s’il n’y a pas d’identifiant, les doublons techniques ne peuvent pas être reconnus dans l’interface source. C’est pourquoi de mon point de vue, le système source devrait être encouragé si possible à adapter la livraison de données.
- Pour des raisons de performance
Si une sous-clé unique est donnée, vous pouvez alternativement définir un autre hub à la granularité plus fine et le connecter proprement via un link comme alternative à un multi-active satellite. Cela permet d’utiliser des patterns standard pour le remplissage et l’interrogation, mais vous devez charger et interroger deux objets supplémentaires.
Raisons pour lesquelles vous ne voulez pas utiliser de Multi-Active Satellites
Un premier défi est qu’un multi-active satellite ne peut être rempli avec des chargements delta que si toutes les lignes pour une hub key sont présentes dans l’extrait delta. Alternativement, des chargements complets sont toujours possibles.
Un autre défi se présente lors de l’interrogation du multi-active satellite avec le hub car la granularité différente cause une duplication des enregistrements du hub (aussi connue sous le nom de fanning-out) — même lors d’une requête pour un assertion time donné.
Enfin, pensez à ce qui se passe si vous voulez créer une PIT pour deux ou plusieurs multi-active satellites sur le même hub. Je suppose que vous finirez dans l’enfer du produit cartésien.
Mais l’argument le plus important à mon avis est, si vous voulez lier à la granularité plus fine, vous devriez créer votre propre hub à partir de cela. Par exemple, considérez les contrats d’assurance : l’instance d’un contrat d’assurance est définitivement un objet indépendant auquel les sinistres peuvent être liés. Ici je modéliserais personnellement toujours un hub contrat et un hub instance de contrat au lieu d’un multi-active satellite.
Proposition de solution pour l’implémentation : Document Satellite
Supposons qu’on ait un cas valide pour implémenter un multi-active satellite — à quoi ressemblerait un bon pattern de chargement ?
Lors de la réunion du German Data Vault User Group (DDVUG) à Hambourg en octobre 2018, Torsten Glunde, Andreas Heitmann, Matthias Müller, quelqu’un dont j’ai manqué le nom et moi avons discuté d’une solution qui résoudrait certains des problèmes d’implémentation :
En supposant que toutes les lignes actives pour une business key doivent être présentes en même temps dans le staging de toute façon, alors vous pouvez créer un ensemble à partir de ces lignes.
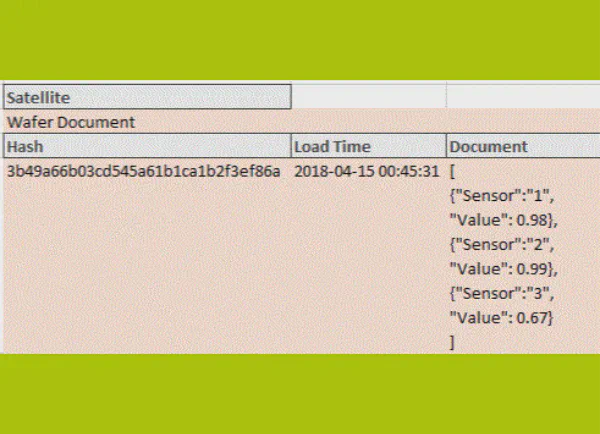
Il existe des bases de données qui permettent les arrays natifs comme types de champ qui peuvent être utilisés pour stocker des ensembles. Plus faisable de nos jours pourrait être un document JSON, qui est déjà supporté sur la plupart des plateformes. En plus des hiérarchies, un document JSON peut aussi représenter des ensembles.
Donc, si vous stockez toutes les lignes dans un document JSON dans un enregistrement satellite, la granularité du hub et du satellite à un assertion time donné correspondra à nouveau. Ainsi, on peut utiliser les mêmes patterns de chargement standard pour tous les satellites.
De plus pour le traitement en aval, il n’y a pas d’augmentation de complexité ni dans la création de PIT ni dans d’autres couches de lecture. Sauf et seulement si vous avez l’exigence métier de résoudre l’ensemble en lignes individuelles (parsing du document JSON dans notre cas), vous pouvez choisir de le faire. Cependant, cela se passe consciemment à l’endroit où c’est désiré.
Documents JSON dans les bases de données
Avec la popularité croissante des documents JSON, il y a aussi de plus en plus de support pour leur gestion dans plusieurs bases de données comme la comparaison binaire dans PostgreSQL. En utilisant cette fonctionnalité, les différences non pertinentes dans le document sont ignorées et un nouvel enregistrement satellite n’est inséré que si quelque chose a effectivement changé dans le contenu.
D’autre part, si votre base de données ne supporte que la comparaison JSON basée sur le texte, vous devrez prendre des mesures actives pour ignorer les différences non pertinentes en utilisant une sorte de prettify.
Épilogue
Utiliser JSON dans les satellites n’est pas nouveau, bien sûr, et peut aussi être utilisé dans d’autres cas : Dan Linstedt lui-même a décrit l’utilisation de documents JSON pour le traitement de données sources dynamiques.
Voir Datavault Builder en action
Démo de 20 minutes. Réponses honnêtes sur l'adéquation avec votre équipe.
Réserver une démo gratuite