Sobre Multi-Active Satellites en Data Vault
Petr Beles sobre la implementación de Multi-Active Satellites como Document Satellites en Data Vault: patrones, compromisos y guía práctica.
Petr Beles, 2150 GmbH 2018-11-07
Implementar Multi-Active Satellites como Document Satellites
En el estándar Data Vault existe un patrón llamado Multi-Active Satellite. También se utiliza en parte para almacenar la bi-temporalidad en el Data Vault.
A una business key en un hub con cierta granularidad se le asigna más de una entrada válida en el satélite para un punto en el tiempo (según el conocimiento DWH o assertion time).
Permítame intentar explicar por qué en ciertos casos se utilizan Multi-Active Satellites, cuándo es mejor prescindir de ellos y cómo se podrían implementar si se decide usarlos de todos modos.
Razones para usar Multi-Active Satellites
- Realmente no hay una clave para distinguir las distintas líneas para la misma business key
En realidad, en mi experiencia esto raramente es así y los datos a menudo se interpretan mal: incluso con un cliente con distintos números de teléfono no clasificados, cada número puede identificarse de forma única: por el propio número.
Además: si no hay un identificador, los duplicados técnicos no pueden reconocerse en la interfaz fuente. Por eso, desde mi punto de vista, debería instarse al sistema fuente, si es posible, a adaptar la entrega de datos.
- Por razones de rendimiento
Si se da una subclave única, alternativamente puede definir un hub adicional en la granularidad más fina y conectarlo limpiamente vía un link como alternativa a un multi-active satellite. Esto permite usar patrones estándar para el llenado y la consulta, pero hay que cargar y consultar dos objetos adicionales.
Razones por las que no quiere usar Multi-Active Satellites
Un primer reto es que un multi-active satellite solo puede llenarse con cargas delta si todas las líneas para una hub key están presentes en el extracto delta. Alternativamente, las cargas completas siempre son posibles.
Otro reto se muestra al consultar el multi-active satellite junto con el hub, porque la granularidad distinta provoca duplicación de los registros del hub (también conocido como fanning-out) — incluso al consultar para un assertion time dado.
Por último, piense en lo que ocurre si quiere crear una PIT para dos o más multi-active satellites en el mismo hub. Asumo que terminará en el infierno del producto cartesiano.
Pero el argumento más importante en mi opinión es que, si quiere enlazar a la granularidad más fina, debería crear su propio hub a partir de ella. Por ejemplo, considere los contratos de seguro: la instancia de un contrato de seguro es definitivamente un objeto independiente al que pueden enlazarse siniestros. Aquí siempre modelaría personalmente un hub contrato y un hub instancia de contrato en lugar de un multi-active satellite.
Propuesta de solución para la implementación: Document Satellite
Supongamos que tenemos un caso válido para implementar un multi-active satellite — ¿cómo sería un buen patrón de carga?
En la reunión del German Data Vault User Group (DDVUG) en Hamburgo en octubre 2018, Torsten Glunde, Andreas Heitmann, Matthias Müller, alguien cuyo nombre no recuerdo, y yo discutimos una solución que resolvería algunos de los problemas de implementación:
Asumiendo que todas las filas activas para una business key deben estar presentes a la vez en staging de todos modos, puede crear un conjunto a partir de esas filas.
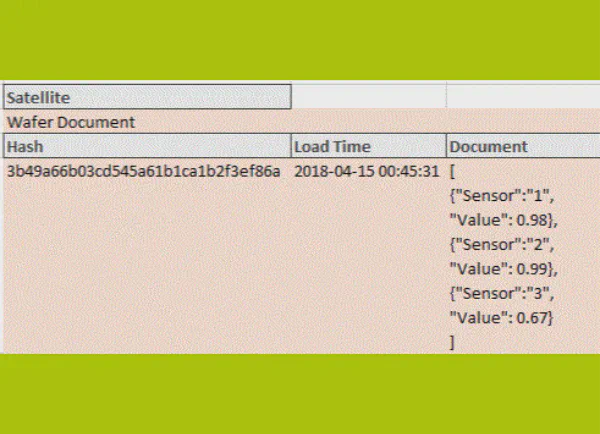
Hay bases de datos que permiten arrays nativos como tipos de campo que pueden usarse para almacenar conjuntos. Más viable hoy en día podría ser un documento JSON, que ya está soportado en la mayoría de plataformas. Además de jerarquías, un documento JSON también puede representar conjuntos.
Así que si almacena todas las líneas en un documento JSON en un registro satélite, la granularidad de hub y satélite en un assertion time dado coincidirá de nuevo. Por tanto, se pueden usar los mismos patrones de carga estándar para todos los satélites.
Adicionalmente, para el procesamiento downstream no hay aumento de complejidad ni en la creación de PIT ni en otras capas de lectura. A menos y solo si tiene el requisito de negocio de resolver el conjunto en líneas individuales (parsear el documento JSON en nuestro caso), puede optar por hacerlo. Sin embargo, esto ocurre conscientemente en el lugar donde se desea.
Documentos JSON en bases de datos
Con la creciente popularidad de los documentos JSON también hay más y más soporte para su manejo en varias bases de datos, como la comparación binaria en PostgreSQL. Usando esta funcionalidad, las diferencias irrelevantes en el documento se ignoran y solo se inserta un nuevo registro satélite si algo ha cambiado efectivamente en el contenido.
Por otro lado, si su base de datos solo soporta comparación JSON basada en texto, tendría que tomar medidas activas para ignorar las diferencias irrelevantes usando algún tipo de prettify.
Epílogo
Usar JSON en satélites no es nuevo, por supuesto, y también puede usarse en otros casos: Dan Linstedt mismo ha descrito el uso de documentos JSON para el procesamiento de datos fuente dinámicos.
Vea Datavault Builder en acción
Demo en vivo. Respuestas honestas sobre si encaja con su equipo.
Reservar una Demo Gratuita